摘要
Our work focuses on tackling the challenging but natural visual recognition task of long-tailed data distribution (i.e., a few classes occupy most of the data, while most classes have rarely few samples). In the literature, class re-balancing strategies (e.g., re-weighting and re-sampling) are the prominent and effective methods proposed to alleviate the extreme imbalance for dealing with long-tailed problems. In this paper , we firstly discover that these rebalancing methods achieving satisfactory recognition accuracy owe to that they could significantly promote the classifier learning of deep networks. However, at the same time, they will unexpectedly damage the representative ability of the learned deep features to some extent. Therefore, we propose a unified Bilateral-Branch Network (BBN) to take care of both representation learning and classifier learning simultaneously, where each branch does perform its own duty separately. In particular , our BBN model is further equipped with a novel cumulative learning strategy, which is designed to first learn the universal patterns and then pay attention to the tail data gradually. Extensive experiments on four benchmark datasets, including the large-scale iNaturalist ones, justify that the proposed BBN can significantly outperform state-of-the-art methods. Furthermore, validation experiments can demonstrate both our preliminary discovery and effectiveness of tailored designs in BBN for long-tailed problems. Our method won the first place in the iNaturalist 2019 large scale species classification competition, and our code is open-source and available at https://github.com/Megvii-Nanjing/BBN.
我们的工作重点是解决长尾数据分布的具有挑战性但自然的视觉识别任务(即少数类占据了大部分数据,而大多数类很少有样本)。在文献中,类重平衡策略(如重加权和重采样)是解决长尾问题的突出而有效的方法。在本文中,我们首先发现,这些再平衡方法之所以能达到令人满意的识别精度,是因为它们能显著地促进深层网络的分类器学习。但同时,也会在一定程度上意外地损害所学深层特征的表征能力。因此,我们提出了一个统一的双边分支网络(BBN),同时兼顾表示学习和分类器学习,每个分支单独执行各自的任务。特别地,我们的BBN模型进一步配备了一种新的累积学习策略,即先学习通用模式,然后逐渐关注尾部数据。在四个基准数据集(包括大规模的不自然数据集)上进行的大量实验表明,所提出的BBN方法的性能明显优于现有的方法。此外,验证实验可以证明我们在BBN中针对长尾问题的定制设计的初步发现和有效性。我们的方法在2019年大型物种分类比赛中获得了第一名,我们的代码是开源的,https://github.com/Megvii-Nanjing/BBN。
背景
尽管re-weighting方法具有很好的预测效果,但这些方法仍然存在不利影响,即它们也会在一定程度上会损害所学习的深层特征(即表征学习)的表征能力。具体来说,当数据极度不平衡时,重采样有过拟合尾部数据(通过过采样)的风险,也有无法拟合整个数据分布(通过欠采样)的风险。对于重加权,它会通过直接改变甚至反转数据呈现频率来扭曲原始分布。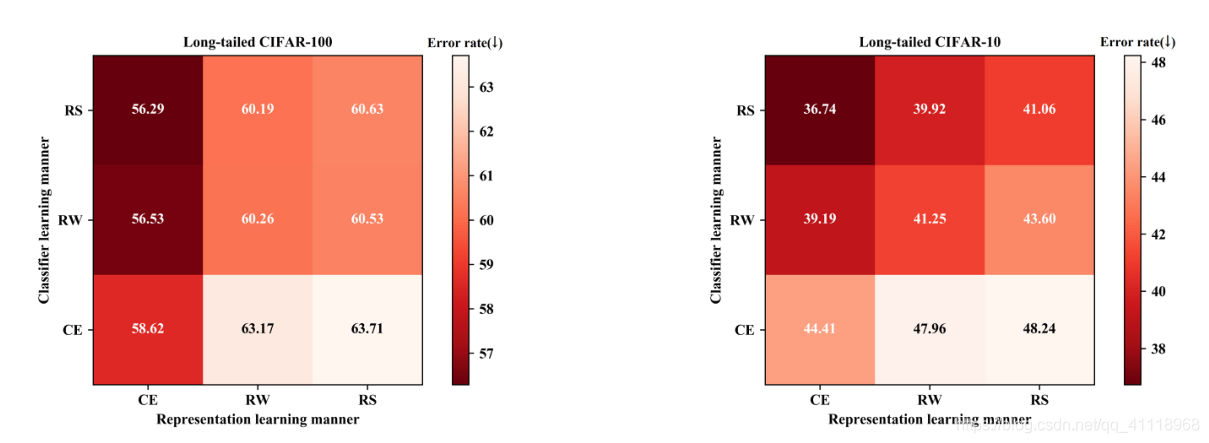
上图表明了平衡策略对特征学习和分类学习的影响。作者采用了简单训练(传统的交叉熵)、重加权和重采样三种学习方式来获得它们相应的学习表示。然后,在分类器学习的后一阶段,首先确定前一阶段收敛的表示学习参数(即冻结主干层),然后对这些网络的分类器(即全连通层)采用前面所述的三种方式进行从头训练。
最终证明:平衡策略会损害表征学习,促进分类学习
具体实现
——————————————————————————————————————————————————
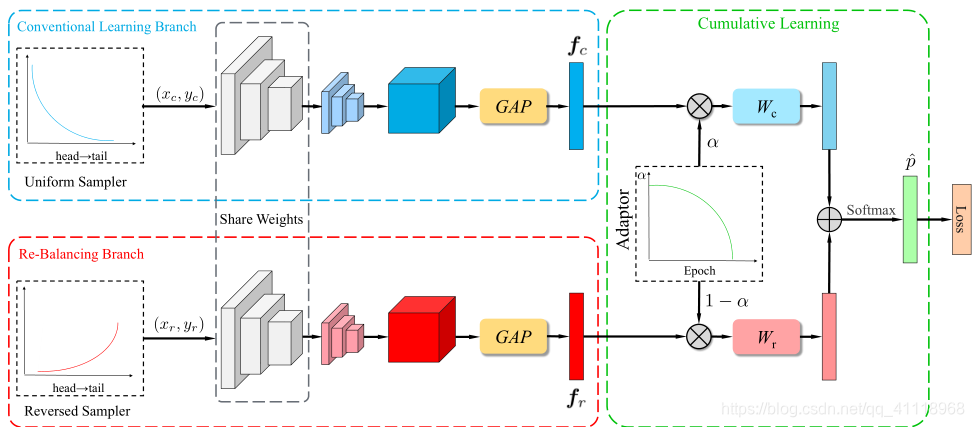
为了彻底提高长尾问题的识别性能,本文提出了一种同时兼顾表示学习和分类器学习的统一双边分支网络(BBN)模型。如上图所示,我们的BBN模型由两个分支组成,称为“传统学习分支”和“重新平衡分支”。BBN的每个分支分别对表示学习和分类器学习履行各自的职责。顾名思义,配备了典型的统一采样器w.r.t.的传统的学习分支学习原始数据分布来对通用模式进行识别。同时,设计了再平衡支路和反向采样器对尾数据进行建模。然后,通过自适应折衷参数α将这些双边分支的预测输出聚合到累积学习部分。α是由“适配器”根据训练epochs的个数自动生成的,它调整整个BBN模型,首先从原始分布中学习全局特征,然后逐步关注尾部数据。更重要的是,α可以进一步控制每个分支的参数更新,例如,在训练后期强调尾部数据时,避免了对所学习的通用特征的破坏。
总体框架
具体来说:两个分支分别用于表示学习和分类器学习,分别称为“传统学习分支(Conventional Learning Branch)”和“再平衡分支”(Re-balancing Branch)。两个分支使用相同的残差网络结构并且共享除最后一个残差块之外的所有权重。设$x .$表示训练样本,$y . \in\{1,2, \ldots, C\}$是它对应的标签,其中$C$是类的数目。对于双边分支,我们分别对每个分支应用均匀和反向采样,并获得两个样本$\left(\mathbf{x}_{c}, y_{c}\right)$和$\left(\mathbf{x}_{r}, y_{r}\right)$作为输入数据,其中$\left(\mathbf{x}_{c}, y_{c}\right)$表示常规学习分支,$\left(\mathbf{x}_{r}, y_{r}\right)$表示重新平衡分支。然后,将两个样本送入各自对应的分支,通过全局平均池化得到特征向量$fc$和$fr$,将两个向量送进累计学习分支,通过随训练迭代次数自调节的$\alpha$来合成新的特征向量,对此向量进行分类学习,合成公式如下:
采样策略
Conventional Learning Branch在一个训练epoch中,训练数据集中的每个样本以相同的概率采样一次。均匀采样器保留了原始分布的特征,有利于表征学习。然而,Re-balancing Branch的目的在于缓解极端的不平衡,特别是提高尾类(tail类)的分类精度,尾类的输入数据来自于反向采样器。对于反向取样器,每个类的采样可能性与其样本大小的倒数成正比,即类中的样本越多,类具有的采样可能性越小。
共享权重
BBN中,两个分支共享相同的残差网络结构。网络除了最后一个残差块,共享相同的权重。共享权重有两个好处:
- Conventional Learning Branch的良好学习表示有利于重平衡分支的学习;
- 在推理阶段,共享权重将大大降低计算复杂度。
累计学习
通过控制两个分支产生的特征的权重和分类损失$L$,$\mathcal{L}=\alpha E\left(\hat{\boldsymbol{p}}, y_{c}\right)+(1-\alpha) E\left(\hat{\boldsymbol{p}}, y_{r}\right)$,在两个分支之间转移学习重心。首先学习通用模式,然后逐步关注尾部数据。$\mathbf{z}=\alpha \boldsymbol{W}_{c}^{\top} \boldsymbol{f}_{c}+(1-\alpha) \boldsymbol{W}_{r}^{\top} \boldsymbol{f}_{r}$。$\alpha$的计算公式为:
推理阶段
将$\alpha$设为0.5,因为两个分支同等重要
消融实验
Re-balancing Branch中使用不同的采样器,反向采样器效果最好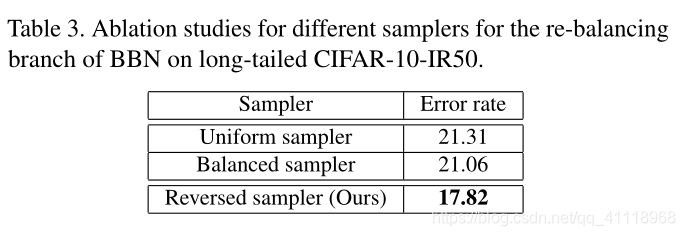
累计学习中$\alpha$的不同降低策略,抛物线最好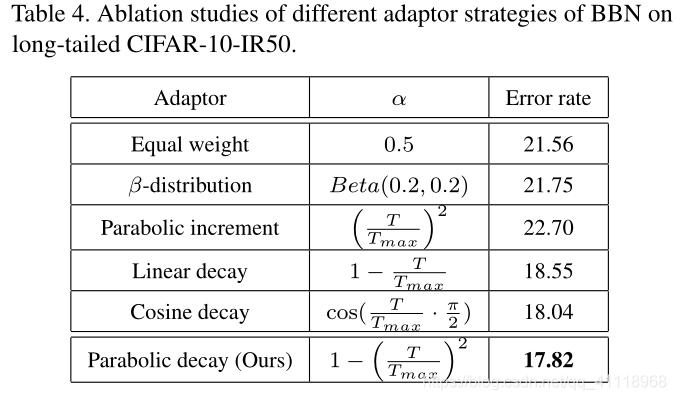
代码实现(自己参照源码写的粗糙的网络)
1 | class Combiner(nn.Module): |

