摘要
Recognizing objects from subcategories with very subtle differences remains a challenging task due to the large intra-class and small inter-class variation. Recent work tackles this problem in a weakly-supervised manner: object parts are first detected and the corresponding part-specific features are extracted for fine-grained classification. However, these methods typically treat the part-specific features of each image in isolation while neglecting their relationships between different images. In this paper, we propose Cross-X learning, a simple yet effective approach that exploits the relationships between different images and between different network layers for robust multi-scale feature learning. Our approach involves two novel components: (i) a cross-category cross-semantic regularizer that guides the extracted features to represent semantic parts and, (ii) a cross-layer regularizer that improves the robustness of multi-scale features by matching the prediction distribution across multiple layers. Our approach can be easily trained end-to-end and is scalable to large datasets like NABirds. We empirically analyze the contributions of different components of our approach and demonstrate its robustness, effectiveness and state-of-the-art performance on five benchmark datasets. Code is available at https: //github.com/cswluo/CrossX.
从具有非常细微差异的子类别中识别对象仍然是一项具有挑战性的任务,因为类内差异很大,类间差异很小。最近的工作以一种弱监督的方式解决了这个问题:首先检测目标部分,然后提取相应的特定于部分的特征进行细粒度分类。然而,这些方法通常孤立地对待每个图像的特定部分特征,而忽略它们在不同图像之间的关系。在本文中,我们提出了Cross-X学习,这是一种简单而有效的方法,它利用不同图像之间和不同网络层之间的关系来进行稳健的多尺度特征学习。我们的方法包括两个新的组成部分:(I)跨类别跨语义正则化,用于引导提取的特征表示语义部分;(Ii)跨层正则化,通过匹配多层预测分布来提高多尺度特征的鲁棒性。我们的方法可以很容易地端到端训练,并且可以扩展到像NABirds这样的大型数据集。我们实证分析了该方法的不同组成部分的贡献,并在五个基准数据集上展示了它的健壮性、有效性和最先进的性能。代码https://github.com/cswluo/CrossX
具体实现
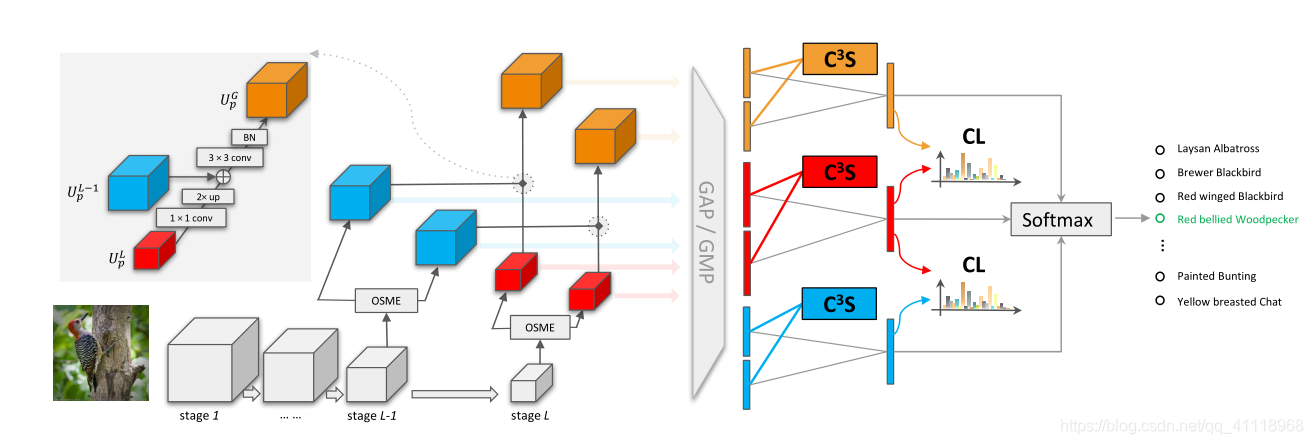
图1.网络架构。我们的网络通过使用osme块输出多个特征地图。在最后两个阶段中,描述了两个OSME块,每个块都有两个激发,以说明我们的方法。来自阶段L−1(蓝色)和L(红色)的特征地图被组合以生成合并的特征图(橙色)。左上角是合并特征图的合并过程的放大显示。然后,通过GAP或GMP聚合特征图以获得相应的集合特征。来自同一阶段的融合特征被C3S正则化相互约束,并且同时被连接以馈送到fc层生成逻辑值。在转换为类概率后,通过CL正则化对逻辑进行约束,并将其组合用于分类。
———————————————————————————————————————
OSME模块
OSME(one-squeeze multi-excitation)模块结合代码和结构图给更容易理解: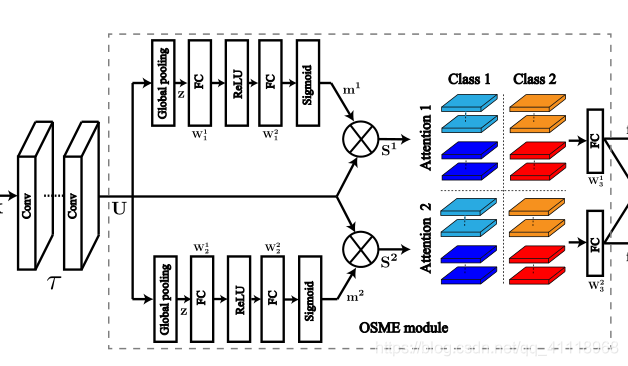
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24class MELayer(nn.Module):
def __init__(self, channel, reduction=16, nparts=1):
super(MELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.nparts = nparts
parts = list()
for part in range(self.nparts):
parts.append(nn.Sequential(
nn.Linear(channel, channel // reduction),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel),
nn.Sigmoid()
))
self.parts = nn.Sequential(*parts)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
meouts = list()
for i in range(self.nparts):
meouts.append(x * self.parts[i](y).view(b, c, 1, 1))
return meouts
设$U=\left[u_{1}, \cdots, u_{C}\right] \in \mathbb{R}^{W \times H \times C}$表示残差块$\tau$的输出特征图。为了生成多个特定于注意的特征图,OSME块通过执行单次压缩(池化)和多次激发(FC)操作来扩展原始残差块。虽然OSME可以产生特定注意力的特征,但引导这些特征具有语义意义是具有挑战性的。
跨类别跨语义正则化($C^{3} S$)
接上(挑战),作者提出通过研究不同图像和不同激励模块的特征映射之间的相关性来学习语义特征。理想情况下,希望从同一个激发模块中提取的特征具有相同的语义含义,即使它们来自不同的带有不同类标记的图像。从不同激励模块提取的特征,即使来自同一幅图像,也应该具有不同的语义。为了实现这一目标,我们引入了跨类别跨语义正则化器($C^{3}S$),该正则化器最大化了来自同一激励模块的特征的相关性,同时最小化了来自不同激励模块的特征的相关性。
图2. $C^{3}S$示例。以中间图像为例,$C^{3}S$通过利用来自不同图像(橙色虚线框)的特征和来自不同激励模块(蓝色阴影框)的特征之间的关系,鼓励在不同语义部分激活激励模块$U1$和$U2$。
———————————————————————————————————————
正则化损失函数公式:
$S_{p, p^{\prime}}=\frac{1}{N^{2}} \sum \mathbf{F}_{p}^{T} \mathbf{F}_{p^{\prime}}$
$\mathbf{f}_{p} \leftarrow \mathbf{f}_{p} /\left|\mathbf{f}_{p}\right|$
$\mathbf{F}_{p}=\left[\mathbf{f}_{p, 1}, \cdots, \mathbf{f}_{p, N}\right] \in \mathbb{R}^{C \times N}$
正则化器即正则化损失,输入是结构图中的同颜色的正方体(特征图),从以下两个部分构造正则化损失:1)最大化$S$的对角线以最大化同一激励模块内的相关性;2)惩罚$S$的范式以最小化不同激励模块之间的相关性;
代码实现:
1 | reg_loss_ulti = RegularLoss(gamma=gamma1, nparts=nparts) |
1 | class RegularLoss(nn.Module): |
跨层正则化($CL$)
利用CNN不同层次的语义特征对许多视觉任务都是有益的。将这种思想推广到细粒度识别的一个简单方法是将不同层的预测结果结合起来进行最终的预测。然而,这种简单的策略通常会导致较差的性能。 我们假设这个问题是由于两个原因造成的:1)中间层特征对输入变化更敏感,这使得它们对于类内变化较大的细粒度识别的鲁棒性降低;2)特征预测之间的关系没有被利用。为了解决这些问题,我们采用特征金字塔网络(FPN)来集成不同层的特征,并提出了一种新的跨层正则化方法($CL$),通过匹配不同层之间的预测分布来学习鲁棒性特征。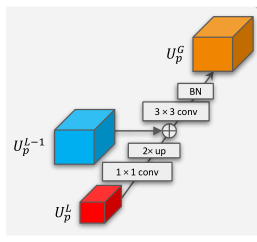
$K1$, $K2$ are 1 × 1 and 3 × 3 filters
Bilinear(·) denotes bilinear interpolation
$\mathbf{U}^{G}$综合了中间层空间分辨率高和顶层语义丰富的特点。为了进一步挖掘特征预测之间的关系,作者提出了匹配不同层之间预测分布的CL正则化器。
$\mathbf{P r}^{L-1}=\sigma\left(f\left(U^{L-1}\right)\right)$
$\mathbf{P r}^{L}=\sigma\left(f\left(U^{L}\right)\right)$
$\sigma\left(·\right)$ is the softmax function
$f\left(·\right)$ denotes the output layer
最终的预测分类可以结合不同模块的输出:
最终损失为:

