摘要
We aim to provide a computationally cheap yet effective approach for fine-grained image classification (FGIC) in this letter. Unlike previous methods that rely on complex part localization modules, our approach learns fine-grained features by enhancing the semantics of sub-features of a global feature. Specifically, we first achieve the sub-feature semantic by arranging feature channels of a CNN into different groups through channel permutation. Meanwhile, to enhance the discriminability of sub-features, the groups are guided to be activated on object parts with strong discriminability by a weighted combination regularization. Our approach is parameter parsimonious and can be easily integrated into the backbone model as a plug-and-play module for end-to-end training with only image-level supervision. Experiments verified the effectiveness of our approach and validated its comparable performance to the state-of-the-artmethods. Code is available at https:// github.com/ cswluo/ SEF
本文旨在为细粒度图像分类(FGIC)提供一种计算量小但效果好的方法。与以往依赖复杂part定位模块的方法不同,我们的方法通过增强全局特征子特征的语义来学习细粒度特征。具体地说,我们首先通过通道排列将CNN的特征频道分成不同的组来实现子特征语义。同时,为了提高子特征的可区分性,通过加权组合正则化,引导分组在可区分性较强的object parts被激活。我们的方法参数很少,可以很容易地集成到主干模型中,作为即插即用模块,用于端到端培训,只需图像级别的监督。实验验证了该方法的有效性,并验证了其性能可与最先进的方法相媲美。有关代码,请访问https://github.com/cswluo/sef
具体实现
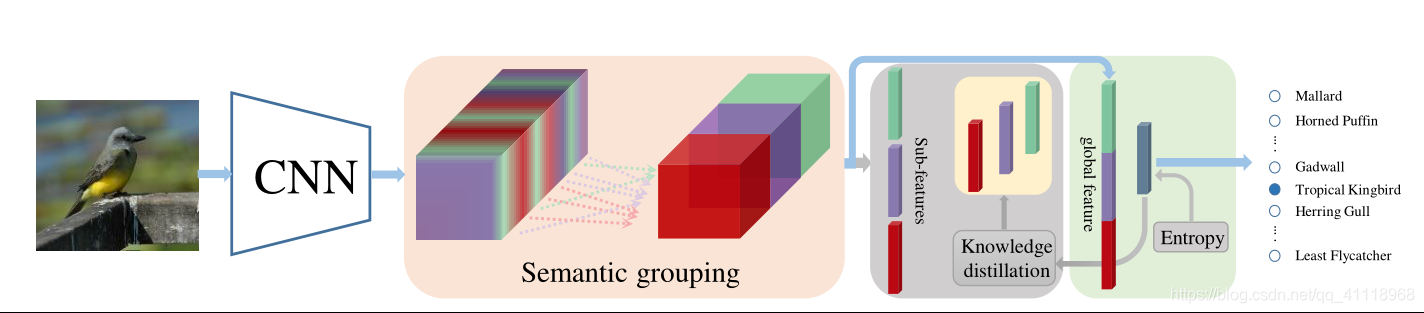
图1.整体框架.
语义分组模块将CNN的最后一层卷积特征通道(用混合色块表示)分成不同的组(用不同的颜色表示)。全局特征及其子特征(分组特征)通过平均池化从排列的特征通道中获得。灰色块中的淡黄色块表示对应的子特征的预测类分布,这些子特征通过knowledge distillation(知识蒸馏)得到的全局特征的输出进行正则化。所有灰块只在训练阶段有效,而在测试阶段去除。为了清楚起见,省略了CNN的细节。
语义分组模块
在CNN的高层中需要使用多个filters来表示语义概念。因此,作者开发了一种正则化方法,将具有不同属性的filters分成不同的组来捕获语义概念。
$\mathbf{X}^{L^{\prime}}$ denotes the feature map with its feature channels arranged by a permutation operation
$\mathbf{A} \in \mathbb{R}^{C \times C}$ is a permutation matrix
$\mathbf{B} \in \mathbb{R}^{C \times \Omega}$ denotes the reshaped filters of layer $\mathbf{L}$,
$\mathbf{X}^{L-1} \in \mathbb{R}^{\Omega \times \Psi}$ denotes the reshaped feature of layer $\mathbf{L-1}$
$\mathbf{W}$ is a permutation of $\mathbf{B}$.
要获得具有语义的组,$\mathbf{A}$应该学会发现B的过滤器(行)之间的相似性。然而,要直接学习排列矩阵并不是一件容易的事。因此,作者直接通过约束$\mathbf{X}^{L^{\prime}}$的特征通道之间的关系来学习$\mathbf{W}$,从而绕过了学习$\mathbf{A}$的困难。为了达到效果,作者最大化了同一组中的特征通道之间的相关性,同时解除了不同组中的特征通道之间的相关性,依靠损失函数 LocalMaxGlobalMin loss:
$\tilde{\mathbf{X}}_{i}^{L^{\prime}} \leftarrow \mathbf{X}_{i}^{L^{\prime}} /\left|\mathbf{X}_{i}^{L^{\prime}}\right|_{2}$作为一个normalized channel
$d_{i j}=\tilde{\mathbf{X}}_{i}^{L^{\prime T}} \tilde{\mathbf{X}}_{j}^{L^{\prime}}$
$\mathrm{D} \in \mathbb{R}^{G \times G}$
$\mathbf{D}$中的元素$\mathbf{D}_{m n}=\frac{1}{C_{m} C n} \sum_{i \in m, j \in n} d_{i j}$
LocalMaxGlobalMin loss 实现代码
1 | class LocalMaxGlobalMin(nn.Module): |
特征增强模块
语义分组可以驱动不同组的特征在不同的语义(对象)部分上被激活。然而,这些部分的可识别性可能得不到保证。因此,需要引导这些语义组在具有很强区分度的对象部分上被激活。实现此效果的一种简单方法是匹配对象及其部分之间的预测分布(即知识蒸馏,我理解成全局和局部之间的分布学习),匹配分布可以利用KL散度。
$\mathbf{P}_{w}$ and $\mathbf{P}_{a}$ are the prediction distributions of an object and its part
(即全局特征和局部特征)
$\mathrm{H}\left(\mathbf{P}_{w}\right)=-\sum \mathbf{P}_{w} \log \mathbf{P}_{w}$
$\mathrm{H}\left(\mathbf{P}_{w}, \mathbf{P}_{a}\right)=-\sum \mathbf{P}_{w} \log \mathbf{P}_{a}$
因此得到这一模块得损失函数:
$\mathcal{L}_{c r}$是全局特征预测的交叉熵损失
将两个模块的损失函数加权相加得到最终的损失:
代码解读
自定义nparts的大小,nparts表示分组的个数,以resnet50主干为例,将layer4输出的特征根据channel均分为nparts份。假设nparts=4,每份channel大小为512。将得到的nparts个特征图分别输入到不同的fc中,得到局部部分的预测xlocal,size为torch.Size([nparts, batchsize, num_classes]。生成一个排列矩阵xcos,输出后依赖此矩阵进行LocalMaxGlobalMin loss计算。
此外,对copy一份layer4输出的特征正常操作,得到全局的预测xglobal,size为torch.Size([batchsize, num_classes])1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64# 添加在Resnet类__init__方法里面
if self.attention:
nfeatures = 512 * block.expansion
nlocal_channels_norm = nfeatures // self.nparts
reminder = nfeatures % self.nparts
nlocal_channels_last = nlocal_channels_norm
if reminder != 0:
nlocal_channels_last = nlocal_channels_norm + reminder
fc_list = []
separations = []
sep_node = 0
for i in range(self.nparts):
if i != self.nparts-1:
sep_node += nlocal_channels_norm
fc_list.append(nn.Linear(nlocal_channels_norm, num_classes))
#separations.append(sep_node)
else:
sep_node += nlocal_channels_last
fc_list.append(nn.Linear(nlocal_channels_last, num_classes))
separations.append(sep_node)
self.fclocal = nn.Sequential(*fc_list)
self.separations = separations
self.fc = nn.Linear(512*block.expansion, num_classes)
—————————————————————————————————————————————————————————————————————————————————
# Resnet类的forward
def forward(self, x):
x = self.conv1(x) # [4,64,224,224]
x = self.bn1(x) # [4,64,224,224]
x = self.relu(x)
x = self.maxpool(x) # [4,64,112,112]
x = self.layer1(x) # [4,256,112,112]
x = self.layer2(x) # [4,512,56,56]
x = self.layer3(x) # [4,1024,28,28]
x = self.layer4(x) # [4,2048,14,14]
if self.attention:
nsamples, nchannels, height, width = x.shape
xview = x.view(nsamples, nchannels, -1) # torch.Size([4, 2048, 196])
xnorm = xview.div(xview.norm(dim=-1, keepdim=True)+eps) # torch.Size([4, 2048, 196])
xcosin = torch.bmm(xnorm, xnorm.transpose(-1, -2)) # torch.Size([4, 2048, 2048])
attention_scores = []
for i in range(self.nparts):
if i == 0:
xx = x[:, :self.separations[i]] # torch.Size([4, 512, 14, 14])
else:
xx = x[:, self.separations[i-1]:self.separations[i]]
xx_pool = self.avgpool(xx).flatten(1) # torch.Size([4, 512])
attention_scores.append(self.fclocal[i](xx_pool))
xlocal = torch.stack(attention_scores, dim=0) # torch.Size([4, 4, num_classes])
xmaps = x.clone().detach()
# for global
xpool = self.avgpool(x)
xpool = torch.flatten(xpool, 1)
xglobal = self.fc(xpool) # torch.Size([4, num_classes])
return xglobal, xlocal, xcosin, xmaps
train,val1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25xglobal, xlocal, xcosin, _ = model(inputs)
probs = softmax(xglobal)
cls_loss = criterion[0](xglobal, labels)
############################################################## prediction
# prediction of every branch
probl, predl, logprobl = [], [], []
for i in range(nparts):
probl.append(softmax(torch.squeeze(xlocal[i])))
predl.append(torch.max(probl[i], 1)[-1])
logprobl.append(logsoftmax(torch.squeeze(xlocal[i])))
############################################################### regularization
logprobs = logsoftmax(xglobal)
entropy_loss = penalty['entropy_weights'] * torch.mul(probs, logprobs).sum().div(inputs.size(0))
soft_loss_list = []
for i in range(nparts):
soft_loss_list.append(torch.mul(torch.neg(probs), logprobl[i]).sum().div(inputs.size(0)))
soft_loss = penalty['soft_weights'] * sum(soft_loss_list).div(nparts)
# regularization loss
lmgm_reg_loss = criterion[1](xcosin)
reg_loss = lmgm_reg_loss + entropy_loss + soft_loss
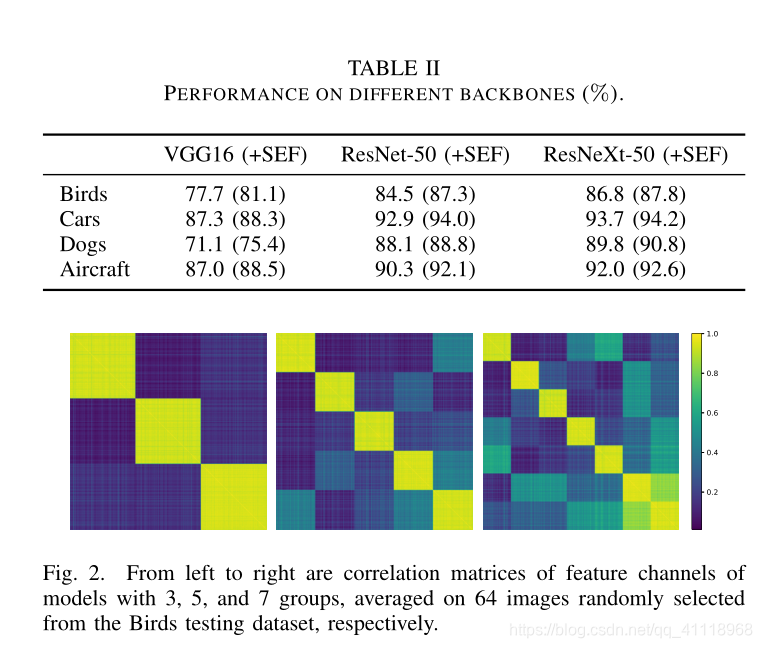
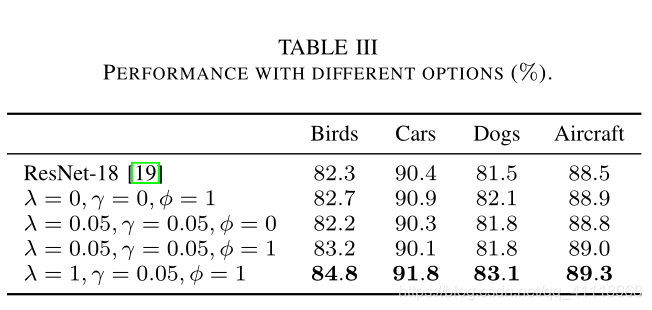
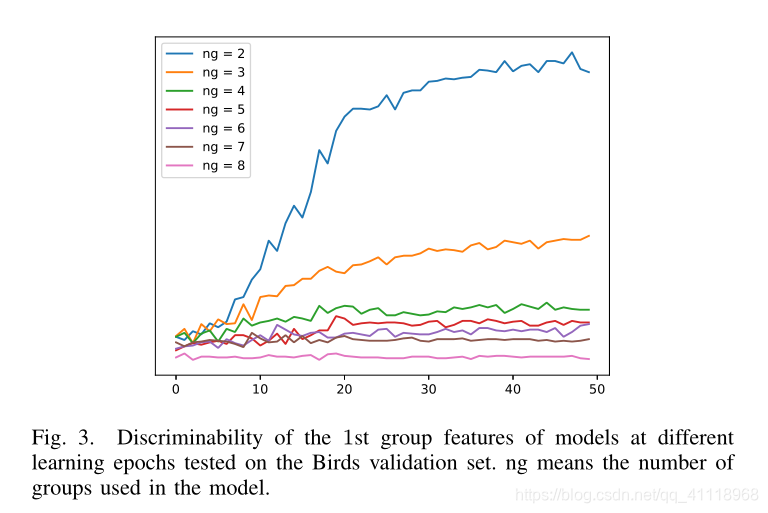
实验效果
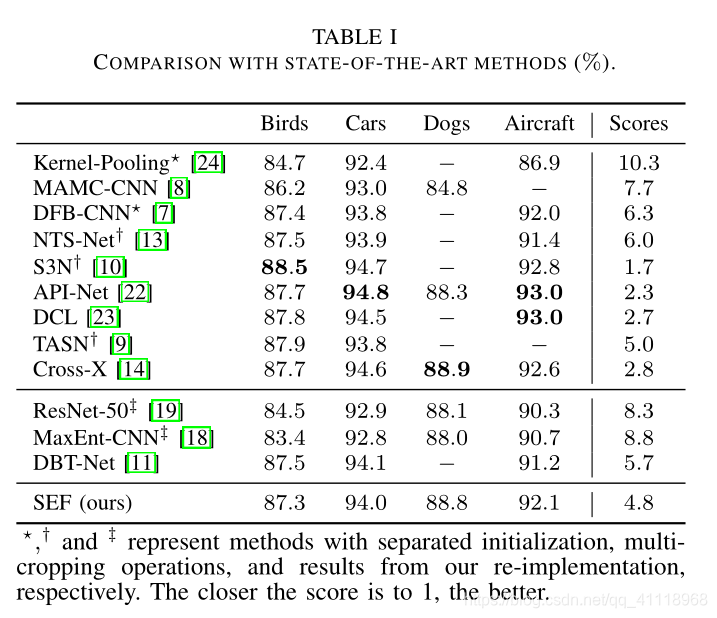
消融实验