摘要
Key for solving fine-grained image categorization is finding discriminate and local regions that correspond to subtle visual traits. Great strides have been made, with complex networks designed specifically to learn part-level discriminate feature representations. In this paper, we show it is possible to cultivate subtle details without the need for overly complicated network designs or training mechanisms – a single loss is all it takes. The main trick lies with how we delve into individual feature channels early on, as opposed to the convention of starting from a consolidated feature map. The proposed loss function, termed as mutual-channel loss (MC-Loss), consists of two channel-specific components: a discriminality component and a diversity component. The discriminality component forces all feature channels belonging to the same class to be discriminative, through a novel channel-wise attention mechanism. The diversity component additionally constraints channels so that they become mutually exclusive on spatial-wise. The end result is therefore a set of feature channels that each reflects different locally discriminative regions for a specific class. The MC-Loss can be trained end-to-end, without the need for any bounding-box/part annotations, and yields highly discriminative regions during inference. Experimental results show our MC-Loss when implemented on top of common base networks can achieve state-of-the-art performance on all four fine-grained categorization datasets (CUB-Birds, FGVC-Aircraft, Flowers-102, and Stanford-Cars). Ablative studies further demonstrate the superiority of MC-Loss when compared with other recently proposed general-purpose losses for visual classification, on two different base networks. Code available at https://github.com/dongliangchang/Mutual-Channel-Loss
解决细粒度图像分类的关键是找到与细微视觉特征相对应的区分区域和局部区域。复杂的网络专门设计用来学习零件级的区别特征表示已经取得了长足的进步。在这篇文章中,我们展示了在不需要过于复杂的网络设计或训练机制的情况下培养微妙的细节是可能的——只需一个损失就可以了。主要的诀窍在于我们如何在早期深入研究各个特征通道,而不是从统一的特征图开始的惯例。所提出的损失函数称为互通道损失(MC-Loss),由两个特定通道的组件组成:判别性组件和差异性组件。判别性组件通过一种新颖的通道注意力机制,强制属于同一类别的所有特征频道具有鉴别性。差异性组件另外约束通道,使得它们在空间上变得相互排斥。因此,最终结果是一组特征通道,每个通道反映特定类别的不同局部区分区域。MC-Loss可以端到端训练,不需要任何额外的bounding box/part标注,并在推理过程中产生高度可分辨的区域。实验结果表明,当我们的MCLoss在公共基础网络上实现时,可以在所有四个细粒度分类数据集(Cub-Birds、FGVC-Aircraft、Flowers102和Stanford-Cars)上获得最先进的性能。消融研究进一步证明,在两种不同的基础网络上,MC-Loss与最近提出的其他用于视觉分类的通用损失相比具有优越性。代码可在https://github.com/dongliangchang/Mutual-Channel-Loss获得
具体实现
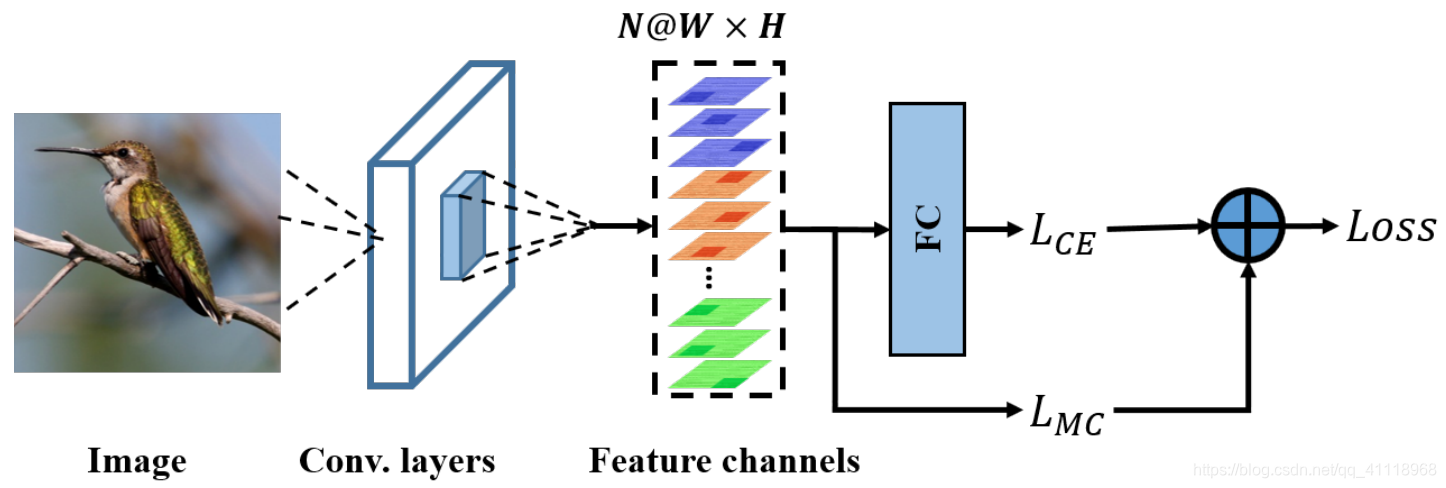
———————————————————————————————————————
将图像输入到基本网络提取特征得到$\mathcal{F} \in R^{N \times W \times H}$,其中需要将通道$N$设置成$c \times \xi$,其中,$c$为类别数量,$\xi$为平坦到每个类上的通道数。
由此第i个类别的特征可以表示为:
之前提取的特征就可以表示为:
随后,$F$进入网络的两个流,其中两个不同的损失针对两个不同的目标定制。在上图中,$L_{C E}$流将$F$视为输入到全连接层中,作交叉熵损失,在这里,交叉熵损失鼓励网络提取主要集中在全局判别区域的信息特征。$L_{M C}$流监督网络聚焦不同的局部区分性区域,对$L_{M C}$做一个加权得到总的损失:
再来具体看$L_{M C}$流: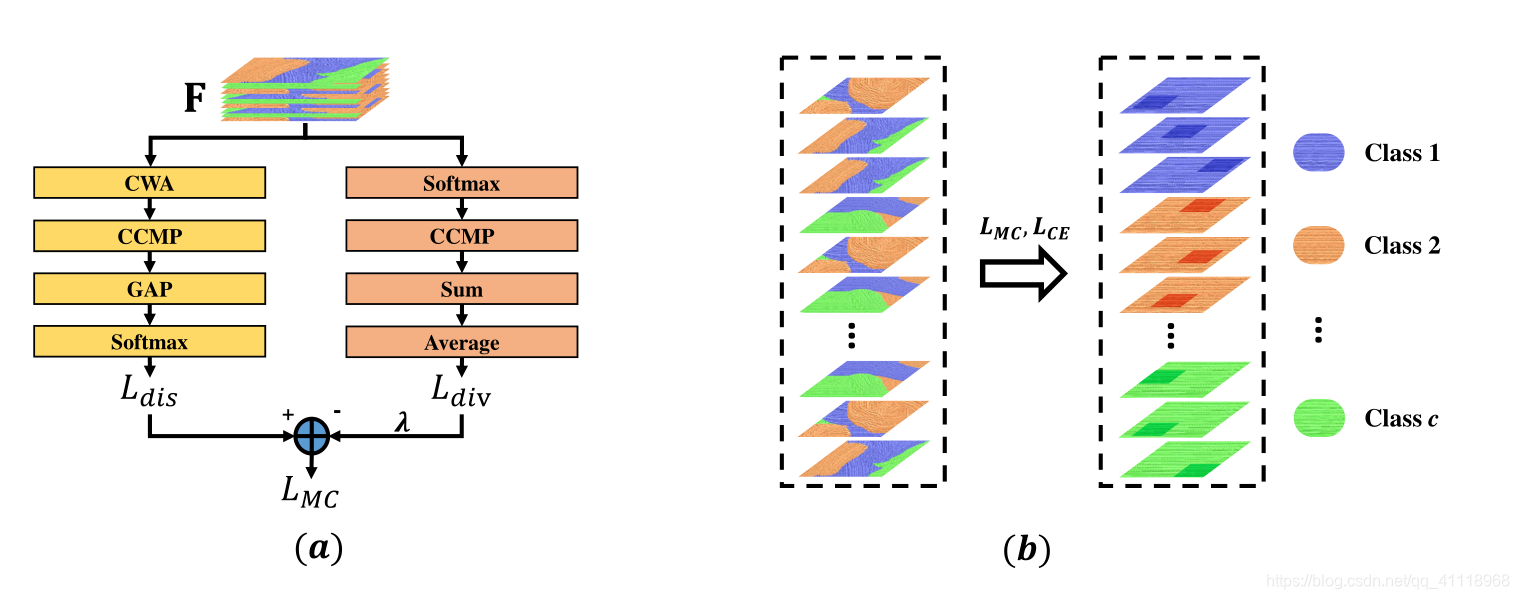
判别组件
上图(a)左,根据前面划分的$\mathbf{F}=\left\{\mathbf{F}_{0}, \mathbf{F}_{1}, \cdots, \mathbf{F}_{c-1}\right\}$,判别组件要求特征通道与类对齐,每个对应于特定类的特征通道都应该具有足够的判别能力。
其中,$g\left(\mathbf{F}_{i}\right)=\underbrace{\frac{1}{W H} \sum_{k=1}^{W H}}_{\text {GAP }} \underbrace{\max _{j=1,2, \cdots, \xi}}_{\text {CCMP }} \underbrace{\left[M_{i} \cdot \mathbf{F}_{i, j, k}\right]}_{\text {CWA }}$;$M_{i}=\operatorname{diag}\left(\right.$ Mask $\left._{i}\right)$;Mask $_{i} \in R^{\xi}$ is a 0-1 mask with randomly $\left\lfloor\frac{\xi}{2}\right\rfloor$zero(s);GAP,CCMP,CWA,分别为Global Average Pooling,Cross-Channel Max Pooling,Channel-Wise Attention。
差异性组件
差异性组件是用于所有特征通道的近似距离测量,以计算所有通道的总相似度。与欧几里德距离和二次复杂度的Kullback-Leibler散度等常用度量相比,在计算复杂度不变的情况下,它的计算成本更低。沿着上图(a)的右侧块所示的差异性组件让组$L_{i}$中的特征通道通过训练变得彼此不同。换言之,一个类别的不同特征通道应该聚焦于图像的不同区域,而不是所有通道都聚焦于最具区分性的区域。因此,它通过使每个组的特征通道多样化来减少冗余信息,并有助于发现针对图像中每一类的不同区分区域。该操作可以被解释为跨通道去相关,以便从图像的不同显著区域捕捉细节。在Softmax之后,通过引入CCMP直接在卷积滤波器上施加监督,然后进行空间维度求和来衡量相交程度。$L_{div}$表示为:
其中,$h\left(\mathbf{F}_{i}\right)=\sum_{k=1}^{W H} \underbrace{\max _{j=1,2, \cdots, \xi}}_{C C M P} \underbrace{\left[\frac{e^{\mathbf{F}_{i, j, k}}}{\sum_{k^{\prime}=1}^{W H} e^{\mathbf{F}_{i, j, k^{\prime}}}}\right]}_{\text {Softmax }}$
代码
1 | def Mask(nb_batch, channels): |
train
1 | out, ce_loss, MC_loss = net(inputs, targets) |
valid
1 | out, ce_loss = net(inputs,targets) |

