摘要
Data augmentation is usually adopted to increase the amount of training data, prevent overfitting and improve the performance of deep models. However, in practice, random data augmentation, such as random image cropping, is low-efficiencyandmightintroducemanyuncontrolledbackground noises. In this paper, we propose Weakly Supervised Data Augmentation Network (WS-DAN) to explore the potential of data augmentation. Specifically, for each training image, we first generate attention maps to represent the object’s discriminative parts by weakly supervised learning. Next, we augment the image guided by these attention maps, including attention cropping and attention dropping. The proposed WS-DAN improves the classification accuracy in two folds. In the first stage, images can be seen better since more discriminative parts’ features will be extracted. In the second stage, attention regions provide accurate location of object, which ensures our model to look at the object closer and further improve the performance. Comprehensive experiments in common fine-grained visual classification datasets show that our WS-DAN surpasses the state-ofthe-art methods, which demonstrates its effectiveness.
为了防止过度拟合并提高深度模型的性能,通常采用数据扩充的方法来增加训练数据量。然而,在实际应用中,随机数据增强(如随机图像裁剪)的效率较低,而且会引入许多不可控的背景噪声。在本文中,我们提出了弱监督数据扩充网络(WS-DAN)来探索数据扩充的潜力。具体地说,对于每幅训练图像,我们首先通过弱监督学习学习生成注意图来表示目标的判别部分。接下来,我们对这些注意力地图引导的图像进行增强,包括注意力裁剪和注意力丢弃。本文提出的WS-DAN算法将分类精度提高了两倍。在第一阶段,由于提取了更多有鉴别能力的零件的特征,因此可以更好地看到图像。在第二阶段,注意区域提供了目标的精确定位,保证了模型更近距离地观察目标,进一步提高了性能。在常见的细粒度视觉分类数据集上的综合实验表明,本文的WS-DAN方法优于现有的方法,证明了其有效性。
具体实现
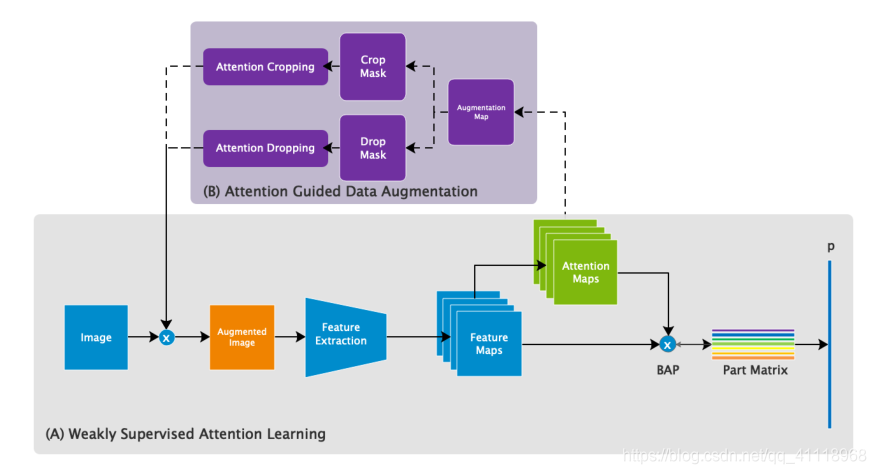
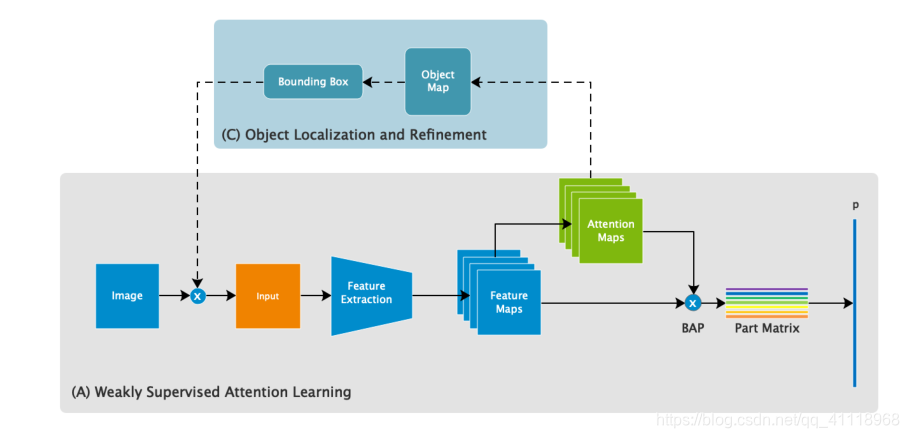
弱监督注意学习
空间表示法
这部分先介绍一些对象的符号表示
特征图 $F \in R^{H \times W \times C}$
注意力图 $A \in R^{H \times W \times M}$ (M<=C),从特征图中获取:
$f$是一个卷积函数(这地方我看的很懵,官方给的代码里面attention map直接选择了前32通道的特征图,$f$即卷积操作没有用到?)
1 | # 获取注意力图的代码 |
双线性池化
作者提出双线性注意池化(BAP)来提取这些零件部位(parts)的特征。首先,将特征图和每个注意力作元素乘法:
然后通过另外的特征提取函数$g(·)$,如全局平均池化(GAP)、全局最大池化(GMP)或卷积,进一步提取有区别的局部特征,得到k个目标特征$f_{k}∈R^{1×N}$,
1 | # 双线性给池化代码 |
Center loss
${c}_{y_{i}}$表示第$y_{i}$个类别的特征中心,$x_{i}$表示全连接层之前的特征。$m$表示mini-batch的大小。因此这个公式就是希望一个batch中的每个样本的特征离特征中心的距离的平方和要越小越好,也就是类内距离要越小越好。

